2022 年 04 月 09 日舉辦的互動網頁設計網聚邀請到許多夥伴來分享,其中很高興邀請到 Projectλ 工作室 Kiva Wu,來跟我們分享聲音編成的相關知識,讓我們能從中認識的聲音設計的考量觀點、效果變化。讓我們一起聽聽看吧!
KIVΛMKII 科幻聲音之旅:經驗分享
大家好,我是 Kiva,我是做聲音工作的,不過這是我第一次講非關聲音主題的專場,所以我現在有點緊張(笑)。今天希望能從我的專業和技術出發,帶大家看看相關的專案,從基礎知識開始,讓大家從聲音的角度理解「設計聲音」這件事情,我在設計聲音的時候也會根據畫面做轉換,這與大家在視覺設計上也許也有共通的地方。
我們先聽一小段我的作品,☞ 前往聆聽(編按:是好聽、有趣也很特別的一段音樂,有興趣的人推薦花個兩分半的時間聽聽看喔!),我會定義自己的曲風是 Cinematic、Base music,我以前是玩樂團的,後來對電子音樂產生興趣,接觸到 EDM、Trance,越聽越深以後就接觸到 base music、mid-tempo,最近很紅的一款遊戲 Cyberpunk 2077 裡面的配樂都是這種類型的音樂。我自己對這樣的曲風以及這樣的曲風如何呈現畫面感或電影的感覺非常有興趣,所以我至今都在專研怎麼做出這樣的效果跟聲音。
我們可以看一下在軟體裡面能夠對聲音做什麼樣的處理跟應用。在數位音樂軟體中,音樂檔案會分軌、線性的方式來呈現,我們在裡面也會用到很多生成式藝術,我們會用聲音作為 source,再用許多不同的效果器讓電腦隨機對這個聲音做出變化。我自己偏好在這個過程之後再加上一個步驟,也就是當聲音生成為不同的段落以後,再透過 audio 的方式將它們剪下來,然後選出我喜歡的段落來使用。這樣就能讓自己設計的 source,再加上 audio 作出的變化,再以自己偏好的方式編排,就能產生非常原創、獨一無二的作品。
我們先大概介紹一下有什麼基本的效果器可以使用,聲音的效果器有非常多種,但其實可以將它們歸納為三個類別:dynamic(動態)、frequency(頻率)跟 space(空間)。通常在設計聲音的時候,可以注意到現在我們在聽音樂的時候大概 95% 以上都是用 stereo 格式,也就是兩個發聲體,但是你必須要創造 3D 的效果給聽眾,有點像是我們在設計 3D 的影像,雖然螢幕是平面的,但可以利用大小、遠近、光影製造出立體的效果。聲音也是一模一樣的概念,我們可以利用聲音的大小、遠近、頻率的高低或空間中的位置不同,讓聽的人感覺到空間,去聽到聲音的位置差異等等,其實是用不同的效果讓大腦產生 3D 的錯覺。
Dynamic(動態)
動態其實是在控制聲音的大小,因此如果這個效果器會對音量產生嚴重的變化,我就會歸類在 dynamic,例如 compress、saturation 等等。
Frequency(頻率)
因為現實空間是 3D 的,聲音也分為三個軸,上下、前後、左右,而 dynamic 控制的是前後軸,一個聲音如果是一樣的狀態,當它越大聲代表離你越近、越小則越遠;而 frequency 控制的則是上下軸,當聲音高頻越多,聽起來就會在音場的上面;低頻越多則會在音場的下面。這跟我們人體如何跟音頻共鳴有關:高頻的聲音是跟鼻腔產生共鳴,低頻的聲音則是跟胸腔共鳴,因此即使你是帶著耳機聽見一個聲音,即使這個聲音並沒有在空間中產生任何震動,我們的大腦也會自動產生高頻在顱腔上方、低頻在顱腔下方的判斷,在腦內建構出音場。因此我們也是利用大腦這樣的特性,在音樂中產生不同的聽覺效果。
Space(空間)
Space 就是左右軸,也就是聲音要多寬?如果一個聲音是 mono 單聲道的,比如說我現在講話是單聲道,但是透過喇叭傳出來、在空間中迴盪的效果,你們聽起來就會是 stereo 立體聲的,也就是你們左右腦聽到的聲音會有些微的差異。當左右腦聽見的資訊有差距的時候,大腦就會認為這是一個立體的聲音。因此假設今天左右喇叭放出來的聲音是一模一樣的時候,大腦就會把它處理成中間訊號。
假設平常有在戴耳機聽音樂或者用喇叭放出來的習慣的話,可以觀察看看,有些音樂的 vocal 或是鼓聲這類的主要元素,會在兩個音場的中間,但是實體空間的中間並沒有喇叭,這就是利用大腦的特性產生的錯覺。
Sound Design(聲音設計)
最後還有一類是 sound design 類,後面時間許可我後面會再多介紹。這種類型是針對聲音的時間軸或生成的東西做一些亂數的變化,讓我們的聲音變得更豐富。如果是用這類生成的技術在處理聲音或設計的話,就會像是在跟電腦對話,因為它會產生什麼其實是沒有辦法控制的。
這也是為什麼我會在聲音處理的流程後再加上一個編排的程序,因為當我在設計聲音的時候需要讓它是合理的、有一定的音樂性。例如是在同一個調性上、或是在一定的節拍中出現,因此我會在流程的後面加上一個將這些亂數的東西排列,讓它聽起來是一個有邏輯的音樂,而不僅是一個聲響。
我自己做音樂的時候會在這兩者之間做調整,讓它不是流行的音樂、但也不完全是聲響,我喜歡抓取中間的平衡點,這是我自己在創作時覺得很有趣的地方。
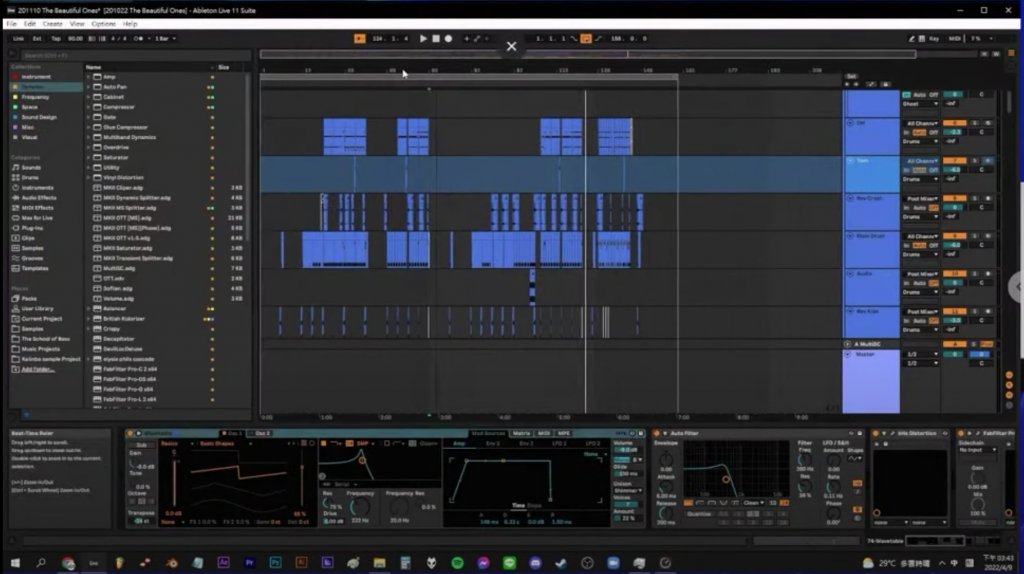
在創作聲音時我會把音軌分成幾大類,畫面上藍色的部分會是節奏類的聲音,如:鼓、鈸等。
在我們設計聲音的時候,通常會有兩種音軌,一個是 audio 軌,一個是 midi 軌。audio 軌跟剪輯影片比較像,當你輸入一段音樂的時候,畫面上會有音樂的波形可以看,能夠看到聲音的大小、形狀等等,midi 軌的話則是會送一段 midi 訊號給電腦,電腦收到訊號以後,就會去讀取 midi 訊號裡的資訊,midi 訊號中主要有音高、 velocity(速率)等訊息,這些不同的參數會傳給電腦,電腦則去找出對應的參數、給出不同的回饋,所以我們可以透過這些細微的參數去調整聲音的變化。
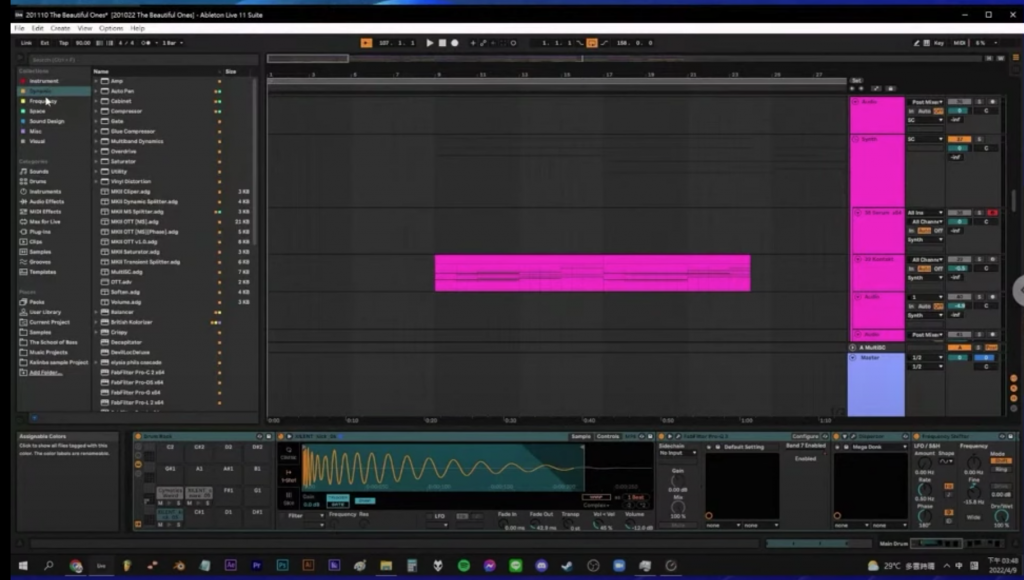
紫色的部分則是我的有機樂器組。我在做聲音的時候喜歡把音樂分成有機跟無機,所謂的無機就是全部都是用合成器做的,在現實生活中比較不可能接觸到的聲音;而有機就是在現實生活中辨識度比較高的聲音,例如人聲、小提琴或是鈸類的聲音等,聽到這類聲音的時候較容易想像對應的樂器是什麼,無機的聲因則比較有序、會覺得是冰冷的,更接近是電腦程式算出來的聲音,比如說合成器產生的聲音全部都是整齊的,在現實世界中比較不容易聽到這樣的聲音。
我們可以這樣理解,當我們想要把一個聲音做得越有機的時候,其實可以讓它隨機性多一點,因為我們現實中很難接觸到很有序的聲音,很有序的聲音通常都是經過設計的,如果我們希望把聲音做的越有溫度、越人性化、越貼近自然的話,隨機性就要高一點。
但如果我們要做音樂,就不能都是隨機的東西,這樣聽眾會無法理解作曲家的意圖,所以為了要跟聽眾有互動感或邏輯感,好像是一種語言般的方式傳遞訊息給他人。
做音樂會分成作曲、編曲、錄音的環節。作曲是先寫出這首歌的概念、旋律或歌詞;接著是編曲,這首歌要是什麼樣的調性?每個段落怎麼安排?配什麼樣的樂器?最後是錄音,歌曲中有些東西如果是需要實錄的,我們就會進錄音室錄音。
但因為現在科技越來越發達,我們許多聲音都能利用電腦模擬出來,像是人聲,雖然也許還能夠聽得出一些破綻,但已經能夠模擬得很像,因此會有 vocal voice、初音這樣的產品,雖然我們聽得出來是電子音,但初音還是成為了一個許多人崇拜的虛擬偶像。
錄音之後會進到混音的環節,比如說 mixing,像畫面上這樣一軌一軌的聲音,我們去做音量上的調整、頻率的調整、三軸上平衡的調整等等,三軸的調整之所以重要,是因為我們在做數位音樂的時候,其實有許多的限制。
比如說:超過 0 分貝會爆掉,所謂爆掉表示上面的音訊已經受損了,電腦無法幫你記錄下來,因為電腦在記錄聲音是有一個固定的量,比如說我現在看一個單獨的音軌波形,桃紅色裡面的音軌有兩個,因為這是一個 stereo 的檔案,上面是左聲道、下面是右聲道,透過聲音的震動變化,電腦會將這個訊號送到喇叭的單體,單體裡面是一個磁鐵,單體根據訊號產生震動,讓我們聽到相應的聲音。

假設我把這個聲音的訊號往上推,堆到一定程度後它會變成平的,也就是超過了一定的值,當它超過一定的值以後,電腦就不會再記錄了,你再看它的波形就會發現有些地方的資訊不見了,這樣的聲音聽起來就會很可怕,會讓人很不舒服。所以我們可以用一些 compressor 或 limiter(限制器)之類的東西去處理它。
效果器
下面我們來介紹一些基本的效果器,瞭解效果器能對聲音做出什麼樣的應用。
之後如果我們講到聲音的動態變化,其實就是在指聲音的最小跟最大聲的差異值。例如說當我們說這段聲音的動態很大,就是在說這個聲音的最小聲到最大聲的差異很大;如果我們說這個聲音沒有什麼動態,表示這段聲音從頭到尾的音量是差不多的。
我們在做聲音時偶爾會需要動態很大的聲音,譬如遊戲的配樂,因為遊戲的前面可能會有人講話的聲音、可能會有其他音效,因此不能讓不同的聲音彼此覆蓋掉。比如說假設我今天在做 PS5 遊戲的配樂,我就不能以一般流行音樂的格式處理,如果這麼做的話,遊戲中其他的聲音加上去之後,就會造成數據超出接受範圍,玩家在玩遊戲的時候就不是一個好的體驗。
我們今天舉例使用一段鋼琴的音樂加上效果器做變化。我們可以使用編輯音樂的軟體裡內建的效果器,若內建的效果器不能滿足需求的話,就會額外使用外部插件(Plug-in)。
插件的部分如果是 Mac,一般我們可以使用 AU(Audio Units)或是 VST,這兩個軟體的格式在影片製作軟裡中也是相容的,因此在影片中若需要對音樂做人聲的處理等等,也能使用這些插件來完成。比如說覺得音樂疊加上人聲變得太大聲,就能夠使用 compressor 把兩個聲音壓縮到同一個音量,讓最後轉出的聲音能夠在容許值的範圍內,觀眾的聽覺體驗比較好。
圖像設計者在使用的圖像編輯軟體中也大多會有 EQ( Equaliser,均衡器) 類的編輯器,用來調整色溫,而在音樂編輯軟體中,也會需要同樣的編輯器,來調整音樂的「色溫」,因為音樂也是有所謂的色彩。通常我們會將高頻的聲音歸類在冷色系,低頻的聲音歸類在暖色系,我自己在設計音樂的時候也是如此,假設今天的畫面是冰冷的,我就會用比較高頻的聲音去點綴;如果要設計的聲音是比較溫暖的,我可能就會用比較低頻的人聲或是大提琴點綴。
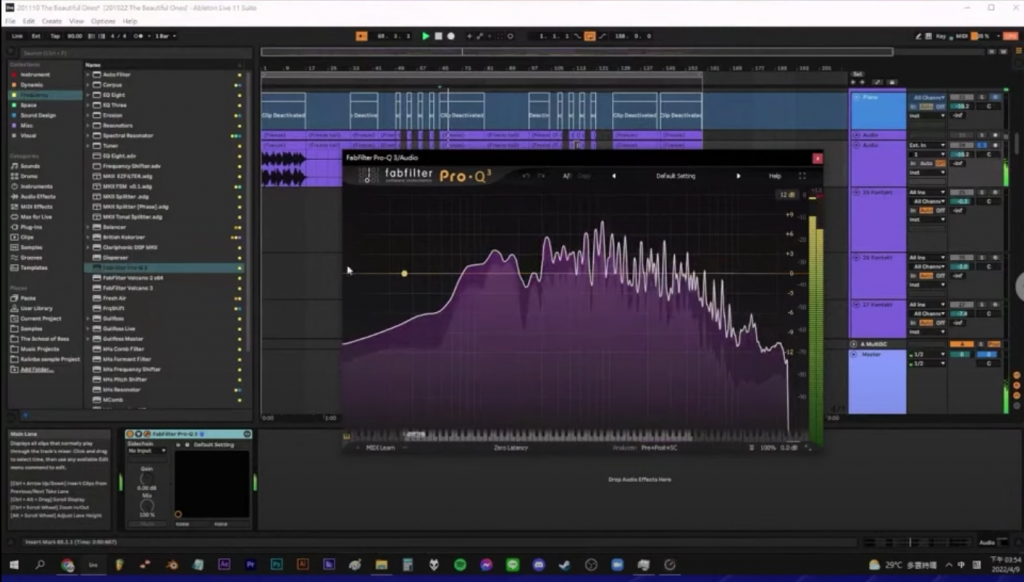
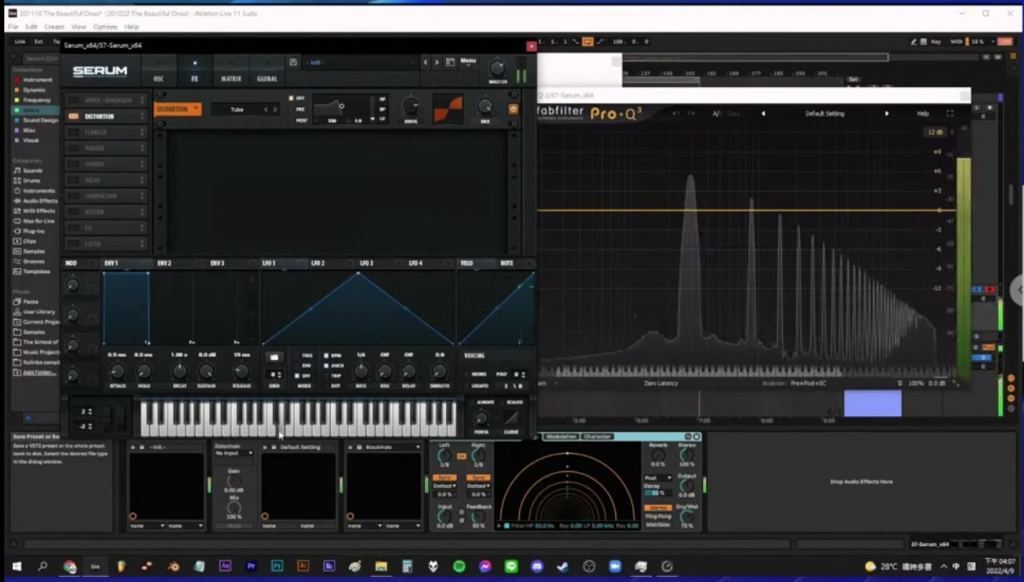
現在畫面中播放的音樂會有一個自動生成的圖像,我們稱之為頻譜,頻譜的左邊是低頻、右邊是高頻,剛剛有談到音樂的三軸,數位音樂在這三軸上有各自的限制。例如說音量有一個表頭的限制,一但超過 0db 就會爆音,而表頭的值是從 0、-1、-2 開始依次遞減,因此超過 0db 的聲音就會產生 clipping 的效果,會聽到的是「劈劈啪啪」的爆音。
第二個限制則是頻率,也就是豎軸的限制。人耳能夠接受音頻的範圍是在 20 赫茲到 20,000 赫茲,超過這個範圍的聲音人耳是聽不到的,也會根據你的年齡增長變窄,因此建議平常有帶著耳機聽音樂習慣的人,不要連續戴超過一個小時,因為超過 28 歲以後,當耳朵的聽覺細胞受損是無法再回復的,所以能聽到的頻率範圍只會越來越窄。
那頻率上的效果器能做的例如把高頻的聲音砍掉,我們叫做低通濾波器(Low-pass filter 或是 high-cut),這樣聲音高頻的聲音就會減少,像我們現場的這個喇叭並不支援低頻聲音,當我經過 filter 把高頻的聲音都砍掉,只剩下 60 赫茲以下的聲音,現場其實是聽不到聲音的,這個動作我們就叫 filter(過濾)。因此當我們覺得一個聲音的高頻太多、覆蓋到其他聲音的時候,我們就能夠透過 filter 過濾掉。
或者我們能夠透過另一種做法 Shelf。例如 high shelf 就是以某一個頻率做基準點,基準點以上的頻率全部做增或減,比如說我將以上的頻率都降低以後,聽眾聽起來會覺得高頻的聲音還留著,但是變小聲了,這樣的效果在音場上產生的作用是,雖然彈鋼琴的人還站在原地,但聲音變遠了,因此聽眾的感覺是這個聲音變得向前傾。我們能針對某一個頻率的聲音做變化,頻率上的調整比單純音量上的變化能讓聲音變得更豐富,讓音樂不會消失或被覆蓋,疊加上其他聲音或人聲的時候也就不會超過容許值。
我們在做 mixing 的時候也就是在做這件事情,比如說我的音樂有 200 軌,要讓這 200 軌能夠同時播放但又不會超出容許範圍且每一個元素都能夠聽得很清楚,這時候我們就會去做 masking,去找出哪一個樂器需要哪一個頻率,保留需要的頻率,砍低其他不需要的頻率並讓給其他聲音,這樣就能讓音樂有立體感,讓所有聲音都存在且能夠清楚地被聽見。
聲音在不同頻率波段產生的效果和色溫其實是不一樣的,當我把同一個聲音的低頻或中低頻的聲音推多一點的時候,聽眾會覺得聲音變暖了;反之如果是高頻推多一點的時候,聲音聽起來變冷、變得比較沒有感情,這就是 EQ 可以做到的事情,EQ 也是在音量之後,最容易去做設計變化的特質。
接下來我們講空間,空間第一個會接觸到的是 delay,第二個是 revert,就這兩個。delay 是能夠複製前一個 source 往後貼上,複製的量如果越多,漸弱就會越久。效果器上有一個值是 dry wave,它代表的是 blend with original,它跟原聲之間的比例是多少,假如我們設定 100%時,就只會聽見複製的聲音,不會聽見第一個原來的聲音;反之全關的話,就只會聽見原來的聲音,不會聽見複製的聲音。因此如果我們開在 50% 的時候,聽眾能夠聽見這兩個聲音是一樣的。
我們也能夠透過速率(rate)去改變原聲跟複製聲之間的間隔,音樂有一個值叫 bpm,代表的是每一分鐘的拍數,比如說 90bpm 代表的是一分鐘有 90 拍,因此我們可以調整音樂的速度,這樣的調整很容易做出一種「聲音很寬」的感覺。
如果有人對聲音設計有興趣,我會推薦從 live 入手,好處是底下的效果器可以串無限顆,對比的是傳統的 DAW(數位音樂工作站軟體)可能會有一些限制,例如一軌只能串 10 顆,但在聲音設計中很容易一軌串到十幾二十顆,所以十顆是絕對不夠用的;live 的第二個好處是可以隨時隨地串聯、並聯,所以我可以一個訊號進去,但是分成兩個不同的效果處理,最後再合併在一起。
動態
那最後我們再看一下動態的變化。動態通常跟設計比較沒有關係,如果要跟設計有關係,要再進到 distortion(失真破音)的環節,除了做動態以外,也能夠做一些泛音,讓聲音變得豐富。在畫面的頻譜中,每一個突起的峰我們叫做「泛音」,如果是 side-wave 的話,後面是沒有泛音序列的,如果有泛音序列的話,我們會覺得這個聲音聽起來是有音色的。
通常人耳在分辨音色的時候,依據的是後面的泛音序列跟它的排列組合與動態,讓我們能夠分辨這是一個鋼琴或是小提琴的聲音。因此即使聽到的同樣是 Do 的音色,我們可以區分這是鋼琴彈出的聲音、或是小提琴拉出的聲音。
頻譜中最左邊的峰代表的是這個音的「基音(fundamental tone)」,因此假如我現在彈一個 Do,畫面上的第一個峰對照下來的就是 Do 的基音,這裡是 261.63 赫茲,因此假如我在 261 赫茲的地方製造一個 side-wave,產生的就是 Do 的音高,基音就是人耳分辨音高的位置。
今天我們粗略分享的就是聲音設計可以對聲音做什麼調配,如果大家對合成聲音或是相關知識有興趣的話,想知道如何從聲音的角度創造畫面的話,我自己有開設私人的課程,大家有興趣的話可以到我的 Facebook:Kiva Wu 了解更多,我們可以一起聊一些跟聲音設計相關的東西。
下面開放給大家 Q&A。
Q & A
Q:想了解 compressor 的使用?
A:好,這個會需要花一點時間讓大家理解。比如說我們現在看到一段音樂的波形,畫面上有的波很小、有的波很大,這個就是所謂的動態差。通常 compressor 正常的使用方式是把大聲的地方壓小,小聲的地方不變,因為假如我把整個音量(volume)變小的話,會連小聲的地方都變小,因此 compressor 可以幫我們做到期望的調整。

當我們把聲音放進 compressor 的時候,你會看到四個主要的參數,包括 Threshold、Ratio、Attack、Release。礙於時間的關係,今天沒有辦法講到 Attack 跟 Release。
Threshold 就是門檻,當音樂超過門檻的時候,compressor 就會把波形往下壓,這樣就能夠讓動態差變小,當動態差變小的時候,就有空間讓我們把音量(volume)一起調大。這個就是 compressor 最基本的用法。
而 Ratio 則是決定我們希望把一個聲音壓小的比例。舉例來說,我們今天的 Threshold 是 -10 db,輸入的聲音是 -6 db,-6 與 -10 差了 4 db,假如今天我們的 Ratio 是 2:1,因此它會把相差的 4db 壓掉二分之一也就是 2 db,因此最後 -6 的聲音會變成 -8 db。原理大概是這樣,也就是太大聲的聲音它會幫你壓小,而小聲的聲音則不變。
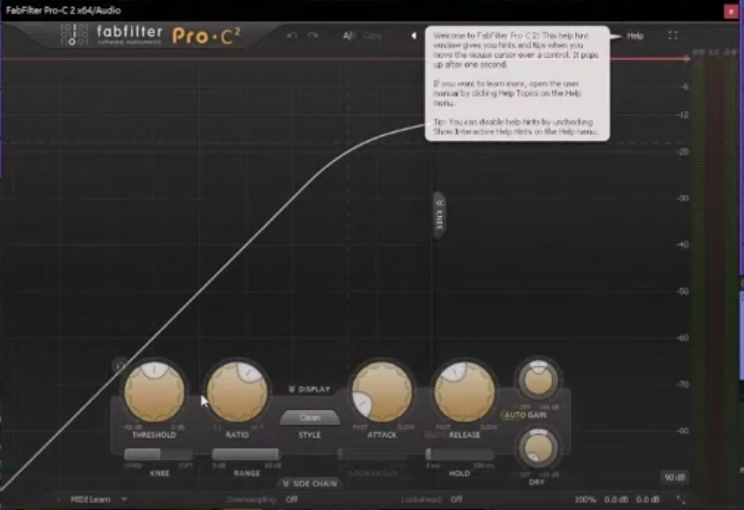
除了 compressor 以外還有很多的動態效果器,比如說 compressor 就有分 upward 跟 downward,downward 就是我們一般熟悉的把大聲的聲音壓小聲。而所謂 upward compressor 就是將沒有超過Threshold(門檻)的聲音拉大聲。
因為我們做聲音的時候會有很多軌,比如說歌手唱到情緒激昂的時候聲音會變得很大,低音或主歌的時候變小聲,而我們希望不要破壞歌手的情緒,但要保留聲音的位置,因此我們會希望把 vocal 保留在動態範圍裡面,讓它不要大聲跟小聲的聲音差距太大,我就能夠透過 compressor 座落在期望的範圍區間裡面。
那今天分享的內容就到這邊,可能比較硬技術一點,希望今天的內容可以幫今天的活動增添一點色彩,也希望大家會喜歡,謝謝。
Kiva 的 StreetVoice:https://soundcloud.com/kivawu
老闆的工商時間
看完分享你會不會對生成式藝術躍躍欲試嗎?老闆在 Hahow 的課程〈互動藝術程式創作入門(Creative Coding)〉教你認識程式與互動藝術產業應用,開啟對工程跟設計的想像,當然還有在直播中提到無數次的,內容扎實程度相當於買到賺到的〈動畫互動網頁特效入門(JS/CANVAS)〉讓你紮實掌握 JavaScript 程式與動畫基礎以及進階互動,整合應用掌控資料與顯示的 Vue.js 前端框架,完成具有設計感的互動網站。歡迎大家看看~
那,我們下次見啦~₍₍ ◝( ゚∀ ゚ )◟⁾⁾
此篇直播筆記由幫手 Kate Chu 協助整理




